
Ssul's Blog
DeepSeek-R1 정리(공부하기) + Open r1 본문
지난 설연휴동안 DeepSeek-R1이 아주 핫하다. 엔비디아 주가도 쭉쭉 빠지고....
이놈의 AI분야는 공부해야 할께 넘쳐난다. 쉬고 싶다 ㅠ.ㅠ
여러 보고서와 논문을 가지고, 구글 NotebookLM과 함께 공부한 내용을 올려본다.
그리고 뽀너스로 deepseek-r1 학습방법을 유사하게 구현한 open-r1프로젝트도 함께 공유하여본다.

#0. DeepSeek-R1의 파급력/성능
많은 블로거들이 정리하였기에 스킵
- 학습비용이 싸다(과연 싼것인가? 상대적으로 싸다)
- 오픈소스다
- 학습방식에서 유의미한 시사점을 던져 줌
알아둘 것은 r1은 추론모델이다. 일반적인 gpt-4o, claude-3.5-sonnet과는 다른 gpt-o1과 같은 계열의 모델이다.
#1. DeepSeek계열 이해하기
1-1. DeepSeek-V3
간단하게 해당 모델은 추론모델이라기 보다는 일반적인 생성모델인 gpt, gemma와 유사한 모델(요즘 모델들이 chat능력도 있어서 chatgpt성능도 가지고 있을것 같기는 하다)
총 6,710억 개의 파라미터를 가지고 있으며, MoE방식을 활용해서, 이중 약 370억개만 활성화 된다.
우선 파라미터가 엄청 크지는 않으며, 실제 활성화되는 파라미터 갯수가 작아서 비용절감
그리고 이 모델을 기반으로 R1-Zero, R1이 만들어지게 된다.
1-2. DeepSeek-R1-Zero
V3에 GRPO라는 강화학습만 실행하여 탄생한 모델. 여기에서 주요 시사점이 등장하는데,
기존의 언어모델은 생성형 모델을 베이스로 해서
- SFT
- RLHF(보상모델, PPO, DPO 등)
를 거쳐서 chatgpt, gemini와 같은 모델이 완성되게 된다.
근데 DeepSeek는 SFT과정을 거치지 않고, 바로 강화학습을 실행하였다고 한다. 그리고 그 성능이 추론모델로 뛰어난 성능을 보여준 것이다.
정리하면 DeepSeek-R1-Zero는 V3모델에 GRPO만 수행하여 괜찮은 추론모델 R1-Zero 제작

1-3. DeepSeek-R1
여기서 연구진은 멈추지 않고, o1을 능가하는 모델을 만들기 위해서 연구를 매진하게 되고, 그 결과 R1이 탄생하게 된다.
위에서 만든 R1-Zero에게 소량의 양질의 CoT데이터를 SFT로 학습을 시킵니다. 그러고 나서 다시한번 GRPO를 진행. 그리고 나서 대규모 데이터로 SFT를 실행. 그리고 또 다시한번 GRPO를 실행
이렇게 해서 그 유명한 DeepSeek-R1이 탄생하게 된다
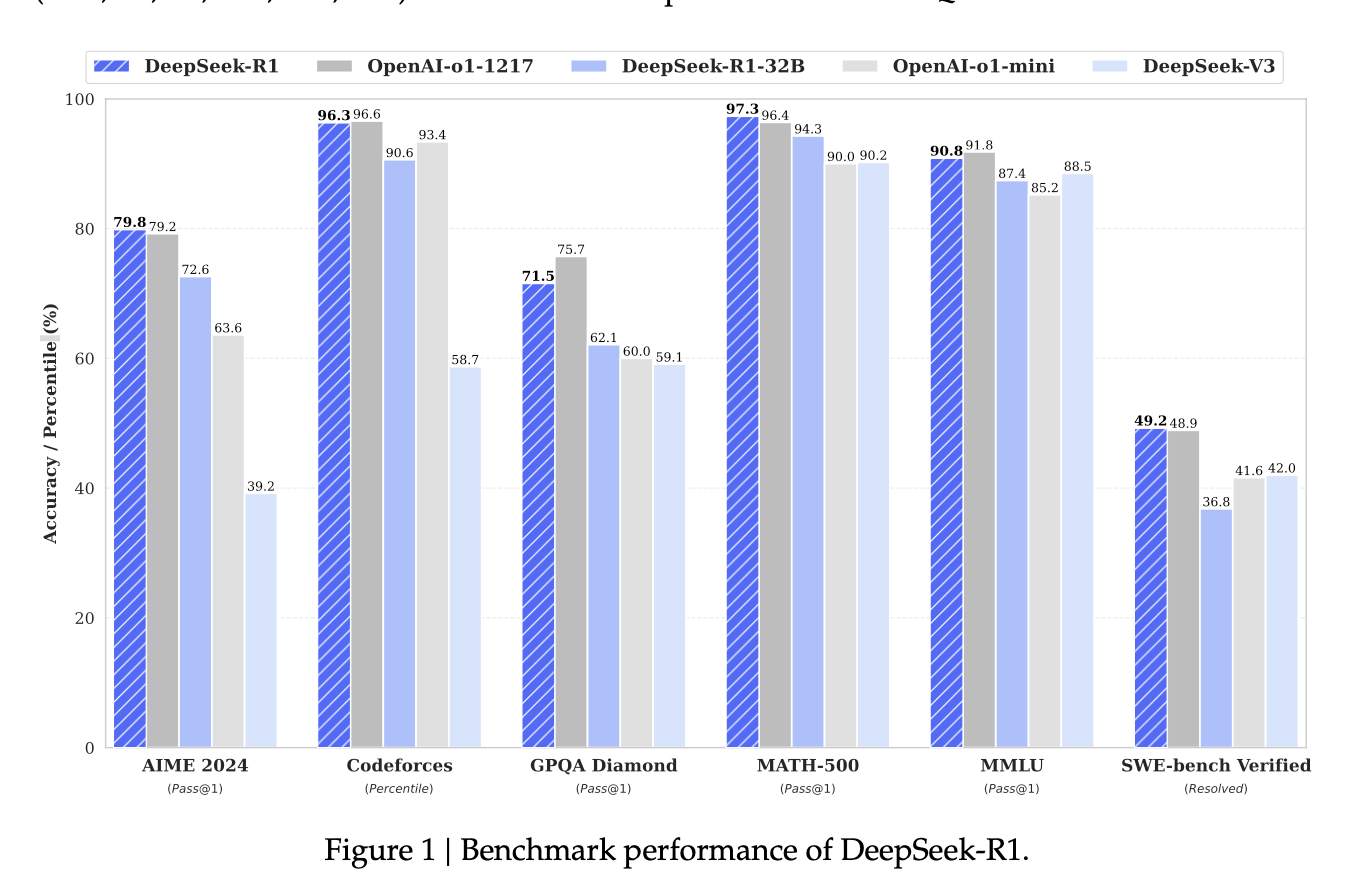
#2. DeepSeek-R1의 학습방법
우선 AI연구자의 입장에서 템플릿 구조가 궁금했고,
GRPO학습 방법이 궁금했다. 나름 이해한 수준에서 정리해 본다.

🔹 DeepSeek-V3 → DeepSeek-R1-Zero (0단계)
- GRPO ①: 순수 강화학습(RL)만으로 훈련 (SFT 없이 GRPO 적용)
- DeepSeek V3-Base 모델을 사용하여 강화학습 기반으로 스스로 CoT(Chain of Thought)를 생성하는 모델을 만듦.
- R1-Zero가 생성됨.
🔹 DeepSeek-R1-Zero → DeepSeek-R1 (1~4단계)
- SFT ① (소량의 CoT 데이터 적용, 수천 개)
- GRPO ②: 첫 번째 RL 적용 (CoT 기반으로 추론 능력 강화)
- SFT ② (대규모 CoT 데이터 적용, 60만 개)
- GRPO ③: 최종 RL 적용 (모델 최적화)
그러면 GRPO의 학습방법은 도대체 무엇인가?
기존 RLHF는 사람이 직접 평가를 해서 보상모델(Reward Model)을 만듬. 그리고, 이 RM이 강화학습을 실행함.
GRPO는 모델이 복수개의 답을 생성하고, 모델이 그 중 괜찮은 답을 평가함.
이 차이가 존재한다. 구체적으로 예시를 들어보면,
학습중인 DeepSeek-R1-Zero(학습중)가 입력된 값에 대해서 복수개의 응답을 출력한다
프롬프트 템플릿 예시
User: "{input}"
Assistant: (Generate N possible responses)
#사용예시
User: "Solve for x: 3x + 7 = 22"
Assistant (Generated Answers):
1. "x = 5. Explanation: Subtract 7 from both sides, then divide by 3."
2. "x = 4. Explanation: Move 7 to the right side, divide by 3."
3. "I am not sure.""input": "Solve for x: 5x - 10 = 20." "output_candidates": [
{
"response": "5x = 30, so x = 6.",
"reasoning": "Add 10 to both sides: 5x = 30. Divide by 5: x = 6."
},
{
"response": "x = 5",
"reasoning": "5x - 10 = 20. Move -10 to the right: 5x = 20, so x = 5."
},
{
"response": "I am not sure.",
"reasoning": "This equation looks complicated. I need more time."
}
]
이렇게 나온 3개의 응답을 다시 DeepSeek-R1-Zero(학습중)에 입력하여 평가를 한다
프롬프트 예시
User: "{input}"
Assistant: "Here are multiple responses to the given question. Rank them from best to worst based on correctness, clarity, and logic. Provide reasoning for the ranking."
Responses:
1. "{response_1}"
2. "{response_2}"
3. "{response_3}"
Ranking and Reasoning:
#사용예시
User: "Solve for x: 3x + 7 = 22"
Assistant: "Here are multiple responses to the given question. Rank them from best to worst based on correctness, clarity, and logic. Provide reasoning for the ranking."
Responses:
1. "x = 5. Explanation: Subtract 7 from both sides, then divide by 3."
2. "x = 4. Explanation: Move 7 to the right side, divide by 3."
3. "I am not sure."
Ranking and Reasoning:
1. "x = 5" - Correct solution with a clear explanation.
2. "x = 4" - Incorrect solution, minor calculation mistake.
3. "I am not sure" - No useful information provided. "evaluations": [
{
"response": "5x = 30, so x = 6.",
"rank": 1 # 정답 (높은 확률로 선택)
},
{
"response": "x = 5",
"rank": 2 # 오답 (확률 낮춤)
},
{
"response": "I am not sure.",
"rank": 3 # 학습 과정에서 제거
}
]
이렇게 받은 평가값을 기반으로 최적의 응답(보상)쪽으로 업데이트
위에를 잘 살펴보면, 결국 학습중인 R1-Zero를 두번 호출한다.
하나는 복수개의 CoT응답을 추출하는 곳에.
두번째는 응답된 복수개의 응답에 평가를 실행하는.
이렇게 GRPO라는 강화학습을 거치면 V3에서 R1-Zero가 탄생한다.
첫번째 GRPO는 "V3를 기반으로 순수 RL로 사고 능력을 터득하는 단계"로 보면 되겠다.
그다음은 1-4단계인
소량 SFT > 다시 GRPO(CoT 기반의 추론 능력을 극대화하는 단계) > 대규모 SFT > 다시 GRPO(최종 모델을 다듬고 최적의 상태로 정렬하는 단계)를 거쳐서 비로소 R1이 탄생하게 된다.
#3. 대규모 추론모델을 Distill한 것 vs 순수base모델을 GRPO 추론능력 비교
결론은 대규모 추론모델을 distill한것이 더 좋다.
그러니 GRPO보다, 우선 좋은 추론 모델을 통해서 지식 증류한 것이 우선.
#4. DeepSeek-R1을 재현하는 open-r1프로젝트
허깅페이스에서 친절하게 딥식이와 동일한 개념으로 학습을 해볼수 있는 코드를 공개하였다.
https://github.com/huggingface/open-r1
GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub.
github.com
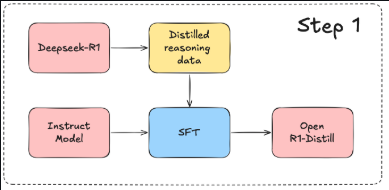
총 3가지 step이 존재하는데,
step1은 DeepSeek-R1을 통해서 추론데이터를 생성한 후, 이 데이터로 지식증류 모델을 만드는 것이다.
예를 들면 DeepSeek-R1-Distill-Qwen-7B는 Qwen-7B모델을 R1모델에서 증류한 데이터로, SFT학습을 하는 것이다.
이는 이후에 step2에서 제작할 순수 GRPO로만 학습한 모델과 비교해 볼수 있겠다.
(#3에서 언급한, 좋은 추론모델의 지식을 습득하는 것이 그냥 일반 모델에 GRPO하는 것 보다 좋다는 것을 보여주는...)
step2는 V3를 R1-Zero로 만드는 과정을 재현한 것이다.
기본모델에 GRPO를 학습시켜서 추론모델인 Open-R1-Zero를 제작하는 것이다.
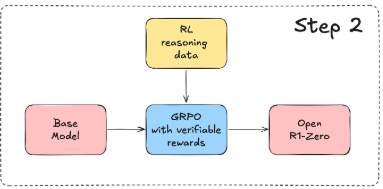
여기서 RL reasoning data는 우리가 위 R1논문에서 봤듯이 학습중인 Open-R1-Zero가 복수개의 응답을 생성하고, 이 응답의 랭킹을 매긴후, 가장 좋은 응답(보상)쪽으로 학습을 하는 것이다.
step3는 SFT와 GRPO를 반복해서 R1을 만드는것처럼, SFT/GRPO를 적용하여 Open-R1를 재현하는 것이다
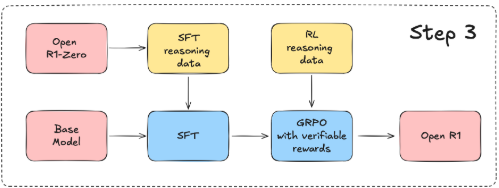
원래 R1의 제작은 R1-Zero에서 출발해서 소규모SFT > GRPO > 대규모SFT > GRPO로 완성되는 형태이지만,
해당 프로젝트는 R1논문에 있는 인사이트들을 반영해서 모델을 제작하는 것이기에 조금 변형해서 만든것 같다.(물론 학습자들의 GPU리소스도 고려해주신것 같다)
지식증류를 통하여 OpenR1-Zero모델에서 추론데이터를 생성하고, 기본모델에 SFT를 진행한다.
그리고 그다음에 GRPO를 실행하여 Open R1을 완성하는 형태.
원래 R1제작에서 cold-start데이터를 사용해서 SFT를 실행하고 GRPO를 실행한 개념을 Step3에 기본으로 넣어두고 있으며, 논문에서 언급했던 distillation방법을 활용해서 SFT용 데이터를 생성해낸 것이 step3의 포인트
이렇게 또 하나의 최근 이슈 학습을 마쳤다. 물론 foundation 모델을 만들고 있지는 않지만, 이런 최신 연구 동향을 따라가다 보면 언젠가는 나만의 모델을 만들때 좋은 인사이트가 되지 않을까 기대해 본다~!
공부 끝!
'AI & ML > 학습하기' 카테고리의 다른 글
| Gemma3 finetuning(파인튜닝)하기 (0) | 2025.03.25 |
|---|---|
| Chat_template 구조 파인튜닝하기(feat. EXAONE-3.5-7B) (0) | 2025.03.07 |
| 패캠(패스트캠퍼스) "LLM 모델 파인튜닝을 위한 GPU 최적화" 후기 (2) | 2024.12.02 |
| 파인튜닝을 통한 감정단어 분류기(NER) (3) | 2024.09.12 |
| AI Product 개발전략과 개발기 (0) | 2024.06.20 |



